



This post is co-authored by George Fraser, the CEO of Fivetran, and Arjun Narayan, the CEO of Materialize. This blog post is cross-posted on the Fivetran blog.
Apache Kafka has brought a lot of value to data stacks as a message broker, log aggregator, and stream processor. Some have argued that it can do even more - i.e., that it can serve as a database in its own right. Here’s why we think that’s a mistake.
What is Apache Kafka?
Apache Kafka is a message broker that has rapidly grown in popularity in the last few years. Message brokers have been around for a long time. They’re a type of datastore specialized for “buffering” messages between producer and consumer systems. Kafka has become popular because it’s open-source and capable of scaling to very large numbers of messages.
Message brokers are classically used to decouple producers and consumers of data. For example, at Fivetran, we use a message broker similar to Kafka to buffer customer-generated webhooks before loading them in batches into your data warehouse:

In this scenario, the message broker is providing durable storage of events between when a customer sends them, and when Fivetran loads them into the data warehouse.
Is Apache Kafka a database?
The database community has occasionally described Kafka as more than just a better message broker. Proponents of this viewpoint position Kafka as a fundamentally new way of managing data; where Kafka replaces the relational database as the definitive record of what has happened. Instead of reading and writing a traditional database, you append events to Kafka and read from downstream views that represent the present state. Some refer to this architecture as ”turning the database inside out“.
In principle, it’s possible to implement this architecture in a way that supports both reads and writes. However, during that process, you’ll eventually confront every hard problem that database management systems have faced for decades.
You will, more or less, have to write a full-fledged DBMS in your application code. And you’ll probably not do a great job because databases take years to get right. You will have to deal with dirty reads, phantom reads, write skew, and all the other symptoms of a hastily implemented database.
Tripping (Up) on ACID
The fundamental problem with using Kafka as your primary data store is it provides no isolation. Isolation means that, globally, all transactions (reads and writes) occur along some consistent history. Jepsen provides a guide to isolation levels (inhabiting an isolation level means that the system will never encounter certain anomalies).
Example
Let’s consider a simple example of why isolation is important: suppose we’re running an online store. When a user checks out, we want to make sure all their items are actually in stock. The way to do this is to:
- Check the inventory level for each item in the user’s cart.
- If an item is no longer available, abort the checkout.
- If all items are available, subtract them from the inventory and confirm the checkout.
Suppose we’re using Kafka to manage this process. Our architecture might look something like this:
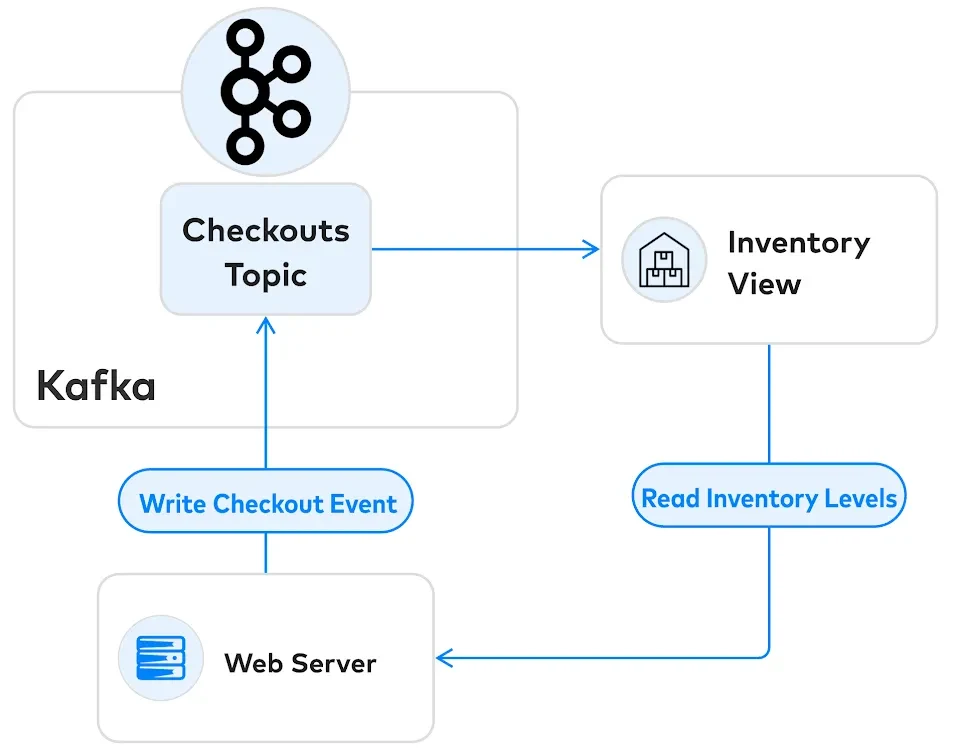
The web server reads the inventory level from a view downstream from Kafka. However, it can only commit the transaction upstream in the checkouts topic.
The problem is one of concurrency control. If there are two users racing to buy the last item, only one must succeed. We need to read the inventory view and confirm the checkout at a single point in time. However, there is no way to do this in this architecture.
Write Skew
This problem is called write skew. Our reads from the inventory view can be out of date by the time we process the checkout event. If two users try to buy the same item at nearly the same time, they will both succeed. However, we won’t have enough inventory for them both.
Event-sourced architectures like these suffer many such isolation anomalies, which constantly gaslight users with “time travel” behavior that we’re all familiar with. Even worse, research shows that anomaly-permitting architectures create outright security holes. These allow hackers to steal data, as covered in this excellent blog post on this research paper.
Don’t Accidentally Misbuild A Database
The database community has learned (and re-learned) some important lessons over several decades. We learned these lessons at the high prices of data corruption, data loss, and numerous user-facing anomalies. The last thing you want to do is to find yourself relearning these lessons because you accidentally misbuilt a database.
Real-time streaming message brokers are a great tool for managing high-velocity data. But you will still need a traditional DBMS for isolating transactions. The best reference architecture for “turning your database inside out” is to use OLTP databases for admission control, use CDC for event generation, and model downstream copies of the data as materialized views.
Using Kafka Alongside a Database
These problems can be avoided if you use Kafka as a complement to a traditional database:
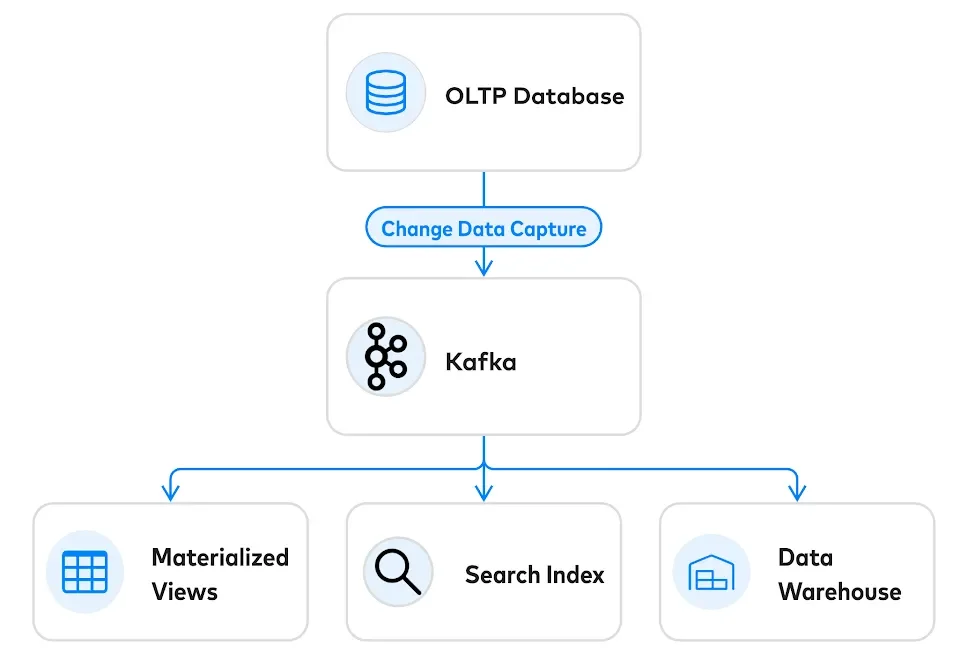
OLTP databases perform a crucial task that message brokers are not well suited to provide: admission control of events. Rather than using a message broker as a receptacle for “fire and forget” events, forcing your event schema into an “intent pattern”, an OLTP database can deny events that conflict, ensuring that only a single consistent stream of events are ever emitted. OLTP databases are really good at this core concurrency control task - scaling to many millions of transactions per second.
Using a database as the point-of-entry for writes, the best way to extract events from a database is via streaming change-data-capture. There are several great open CDC frameworks like Debezium and Maxwell, as well as native CDC from modern SQL databases. Change-data-capture also sets up an elegant operational story. In recovery scenarios, everything can be purged downstream and rebuilt from the (very durable) OLTP database.
The Materialize approach for using Kafka
Materialize is an operational data store built specifically for real-time use cases. Customers use Materialize to provide rapid access to data to power logistics, anomaly detection, inventory management, and personalization, among other uses.
Using Materialize, you can easily create a Kafka connector and generate a materialized view from the incoming data. Materialize handles all of the complexity of ingesting messages from Kafka streams - all your downstream data consumers need to do is query the resulting view using standard SQL.
You can also use Materialize with a Kafka-compatible serverless broker, such as Redpanda. This enables you to stand up a stream processing solution without the complexity of managing Kafka’s multiple components.
If you’re interested in getting fully consistent views of your Kafka data updated in real-time, try out Materialize to see if it’s the right solution for you.

