


In our last blog on small data teams, we discussed the challenges they face when building streaming solutions. The limitations of the modern data stack require small data teams to build their own streaming services, but they often lack the time, resources, and skills to do so. In this regard, large teams have the advantage.
But with the emergence of the operational data warehouse, small data teams can now leverage a SaaS solution with streaming data and SQL support to build real-time applications. In the following blog, we’ll discuss how operational data warehouses level the playing field for small data teams.
Make sure to download the full white paper — Real-Time Data Architectures for Small Data Teams — for a complete overview of the topic.
Small Data Teams: Why They Struggle to Build Streaming Solutions
The modern data stack has helped level the playing field between small teams and large teams. Before the cloud revolution, monolithic, on-premise data warehouses required large teams for deployment and maintenance. However, small data teams can now leverage the ease-of-use, scalability, and speed of the cloud-native modern data stack to grow as easily as large teams do.
But for real-time data operations, team size begins to matter. Small teams are at a disadvantage. Building out a streaming solution is usually easier with a ten person team than a two person team. The large team has the skills sets, time, and budget to implement complex streaming solutions. Once small teams lose the convenient SaaS tools of the cloud data stack, they’re responsible for building their own streaming data architecture. And this is difficult for a number of reasons.
At the most basic level, small teams simply don’t have enough hours in the day to build a complicated streaming solution. Small teams are too busy dealing with ad hoc requests, triaging data infrastructure issues, and clearing out the data queue to consistently focus on such a massive project.
Even when a streaming solution is live, small teams still need to perform maintenance and expand operations to sustain business activities. This adds a constant burden on the data team, one that they don’t have time for. They’re too busy filling the urgent data needs of the organization.
Small teams also lack the necessary skill sets for building streaming solutions. Solutions such as Flink and Kafka Streams require knowledge and experience not typically possessed by small data teams. In contrast, large data teams have personnel who either have these skills, or have time to learn them.
The lack of full SQL support makes it difficult for these teams to build streaming solutions. Streaming services usually require experience with programming languages that are unfamiliar to these teams, such as Java or Scala. Small teams also need to learn about other unfamiliar topics, including APIs for stream processors, data sinks, and streaming SQL concepts.
Even when small teams have the right skill sets, they often lack the resources to create and manage streaming solutions. Budgets for small teams are likely small as well, and the costs of running stream processors are high. This puts streaming solutions out of reach for most small teams.
Hiring new talent, managing the system, and servicing complex architectures all make stream processors an expensive solution. Also, stream processors are not a database, and they require a separate system to store and serve the data. For small data teams on a limited budget, the cost is too high.
Overall, small teams lack the time, the skills, the personnel, and the budget to build and maintain stream processors. That’s why large data teams are often better positioned to implement stream processors. In terms of streaming solutions, small teams really need the SaaS technologies that brought them closer to parity with large teams.
And with the emergence of operational data warehouses, these teams can finally leverage a cost-effective SaaS solution for streaming data.
Operational Data Warehouse: Streaming Solution for Small Teams
Building a streaming solution from scratch is difficult for small teams. But a rising SaaS solution — the operational data warehouse — brings the flexibility and ease of the cloud data stack to small teams in the form of a real-time data warehouse.
Operational data warehouses such as Materialize combine streaming data with extensive SQL support, allowing small teams to continuously transform data at a fraction of the cost. Small data teams harness Materialize to power real-time use cases such as fraud detection, personalization, and alerting.
Materialize is a data warehouse that updates data in real-time, rather than in batch. By employing change data capture (CDC), Materialize refreshes data as soon as it changes in a source database, enabling access to the most up-to-date results at all times. This stands in contrast to batch data warehouses, which typically update data a few times per day, not fast enough for real-time use cases.
Materialize enables small teams to execute their SQL queries against real-time data with millisecond latency and sub-second freshness. Unlike streaming databases, Materialize offers full SQL support, including efficient multiway joins, outer joins, window functions, and recursive SQL. This empowers the data team to easily access and utilize the data warehouse.
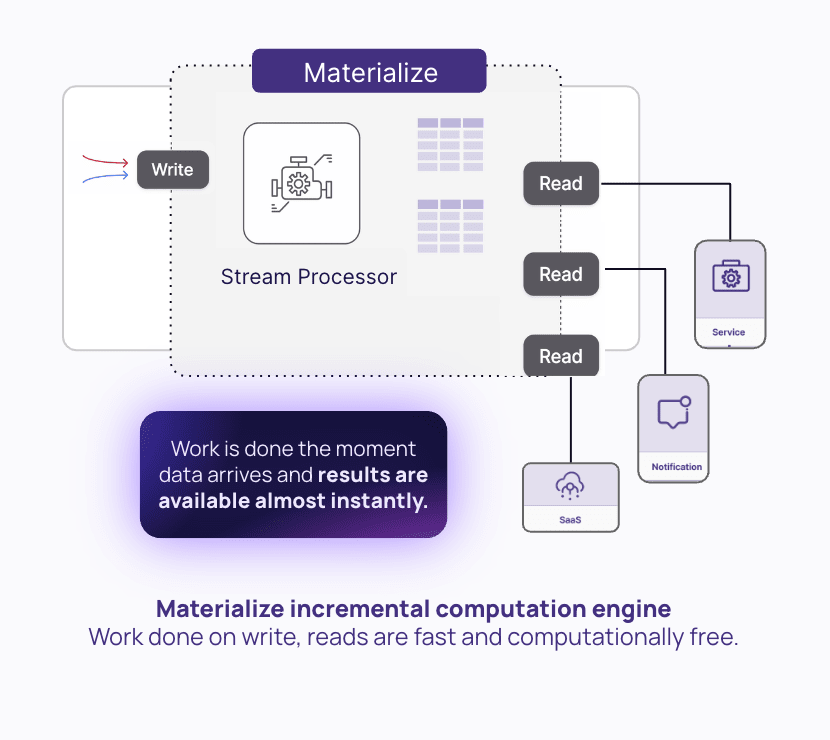
With analytical data warehouses, executing SQL queries with high frequency will drive up compute costs considerably. Materialize is designed to avoid this kind of constant query recomputation. Instead, Materialize leverages incremental view maintenance to decouple the cost of compute and data freshness.
Materialize incrementally updates materialized views and indexes in a long-running dataflow to keep them fresh. Instead of re-running the query repeatedly, Materialize only updates the data that has changed. By doing a small amount of work continuously instead of a large amount of work all at once, Materialize is able to provide excellent performance while making efficient use of compute resources.
Here’s how Materialize solves some of the core problems small data teams face when building a real-time data architecture.
No SQL Support | SQL Support
Small teams often lack the skill sets needed to build and operate streaming solutions. Many stream processors require knowledge of Scala and other specialized programming languages. Some streaming systems implement partial SQL, but foreign concepts make these technologies difficult to use. Small data teams often do not possess the programming skills or experience required to build these systems.
Operational data warehouses offer full SQL support, enabling easy accessibility for small teams. This allows non-specialists to access and manipulate data and create data models as they would with any other data warehouse. Small teams can also port SQL logic from their old data warehouses directly onto their operational data warehouse and start running in production rapidly. Materialize facilitates these transfers with a dbt connector and full PostgreSQL wire compatibility.
Not Enough Time | Pre-Built Solution
Small teams do not have time to build a stream processor from scratch. Most small teams are already overwhelmed by data requests, and cannot devote themselves to such a sprawling project. As a result, small data teams forgo building streaming services, and instead push their analytical data warehouses to the brink.
With operational data warehouses like Materialize, these teams don’t have to spend any time building a streaming solution. Materialize is a pre-built SaaS platform, allowing small teams to use streaming data in their workflows immediately. SaaS also means no maintenance, provisioning, or other manual tasks, so teams don’t waste their hours on system upkeep.
Costs Too Much | Cost-Effective
With analytical data warehouses, small teams often encounter cost issues when running real-time use cases. This is because analytical data warehouses operate with a pay-per-query pricing scheme. Since real-time use cases require continuous query outputs, the cost is too burdensome for small teams.
However, small data teams can also continuously transform data at a cost-effective rate with an operational data warehouse. This allows them to power real-time business processes, such as anomaly detection, with a constant stream of fresh query outputs. Since cost is decoupled from query execution, the price is affordable for small teams.
Hire More Personnel | Use Existing Skills
When a small team decides to build a custom streaming solution, they often need to hire expert talent to complete the project. Small teams don’t have the time or technical knowledge to create streaming systems. As a result, the total cost of ownership (TCO) for streaming solutions is much higher, given the added personnel costs.
However, with an operational data warehouse, small teams don’t need to hire more personnel. The managed SaaS service, full support for SQL, and other features make operational data warehouses accessible, easy to use, and less intensive to maintain. All of this results in reduced hiring.
Download the Free White Paper
As consumers demand more real-time experiences, there is increased pressure for small data teams to acquire streaming solutions. Historically, these teams lacked the time, skills, personnel, and funds to build streaming systems. Meanwhile, large teams got a head start on building real-time data architectures, since they had more team members, resources, and budget.
With an operational data warehouse, small teams can easily access real-time data architectures for the first time. Operational data warehouses are built with the same convenient SaaS architecture as other tools in the modern data stack. They are affordable, easy to set up and use, and more accessible than manually built stream processors. Now small data teams can scale faster than large teams that rely on clunky and expensive self-built streaming solutions.
If you liked this blog, download the complete white paper — Real-Time Data Architectures for Small Data Teams — for a full overview of the topic.

