



An operational data store (ODS) can perform queries that are fresh and also data intensive. This allows ODS to power operational use cases such as fraud detection, loan underwriting, and alerting. However, building an ODS from disaggregated parts is difficult. Creating streaming services from scratch is expensive, time-consuming, and complex. Also, streaming applications are not written in SQL, but require knowledge of Scala, Java, and abstruse database concepts.
This is why teams adopt ODS platforms. However, standard ODS platforms often lack the ability to ingest data from many different sources. The data needs to be fresh, and this adds to the challenge. Getting more data sources for an ODS can unlock many new use cases that require fresh data.
Materialize is an operational data store that excels at data and query-intensive workloads, harnessing fresh and consistent data at scale without burdening your primary database. For us, one of the most requested OLTP sources is Oracle. And with our new integration with Estuary Flow, teams can now ingest Oracle data and many other sources that were previously unavailable.
The integration between Estuary Flow and Materialize makes fresh data not only possible, but easy to implement as well. You can now stream virtually any data into Materialize and run operational use cases such as offloading queries, operational data mesh, and joining streaming data, all while using SQL.
In this tutorial, we’ll guide you through ingesting Oracle data into Materialize via Change Data Capture (CDC) in just a few minutes using Flow’s new Kafka API compatibility layer, Dekaf.
What is Change Data Capture (CDC)?
CDC, or Change Data Capture, is a mechanism used to capture operations in a database (e.g. inserts, updates, and deletes) and propagate them to an external system in real time.
This allows the external system to stay in-sync with the upstream database as new changes occur. CDC is the most common foundation for data replication, data integration, and real-time analytics.
Estuary Flow
Estuary Flow is a platform built specifically for CDC and real-time streaming. It excels at capturing data from various sources and delivering it to numerous destinations for analytics, operations, and AI. With its event-driven architecture, Estuary Flow ensures data is processed and delivered exactly once, with low latency, making it an ideal solution to use with Materialize.
Some key features of Flow include:
Fully Integrated Pipelines: Flow simplifies data integration by enabling you to create, test, and change pipelines that gather, modify, and consolidate data from multiple sources.
Change Data Capture (CDC): Always-on CDC that replicates in real-time with exactly-once semantics, backed by cloud storage in your own private account.
No-Code Connectors: With 150+ pre-built connectors for popular data sources and sinks, such as databases and message queues, Flow reduces the need for custom connectors. This speeds up data pipeline deployment and ensures tooling consistency across systems.
How Does Dekaf work with Materialize?
With Dekaf, you can connect any destination via its existing Kafka API support to Estuary Flow as if it’s a Kafka cluster. Estuary Flow is 100% Kafka-API compatible. Just connect, choose your topics, and start to receive messages.
Materialize supports native CDC connectors for PostgreSQL and MySQL, but requires additional tooling to ingest CDC from other source databases. One of the most common ways to ingest CDC into Materialize is by using Kafka and Debezium. Despite being a popular CDC architecture, operating Kafka can be cumbersome, and using Debezium comes with some trade-offs that not all use cases can tolerate.
Kafka API compatibility was the last piece needed to make the integration between Flow and Materialize totally seamless. There is no need for any coding, as this functionality is already available out of the box. Configuring both takes just a few minutes and opens the door to smoother, easier CDC ingestion from databases that aren’t natively supported in Materialize, like Oracle and SQL Server.
Tutorial: Real-time CDC from Oracle to Materialize
The rest of the tutorial will contain step-by-step instructions on how to build an end-to-end CDC pipeline. You’ll learn how to:
Configure a capture in the Estuary Flow dashboard to ingest change events.
Set up Estuary Flow as a source in Materialize and transform data in real-time.
Prerequisites
Register for an Estuary Flow account here. There’s also the Estuary Slack channel for support.
Sign up for a free trial of Materialize here.
Step 1: Create Oracle Capture in Estuary Flow
Head over to the Estuary Flow dashboard and create a new Oracle capture.
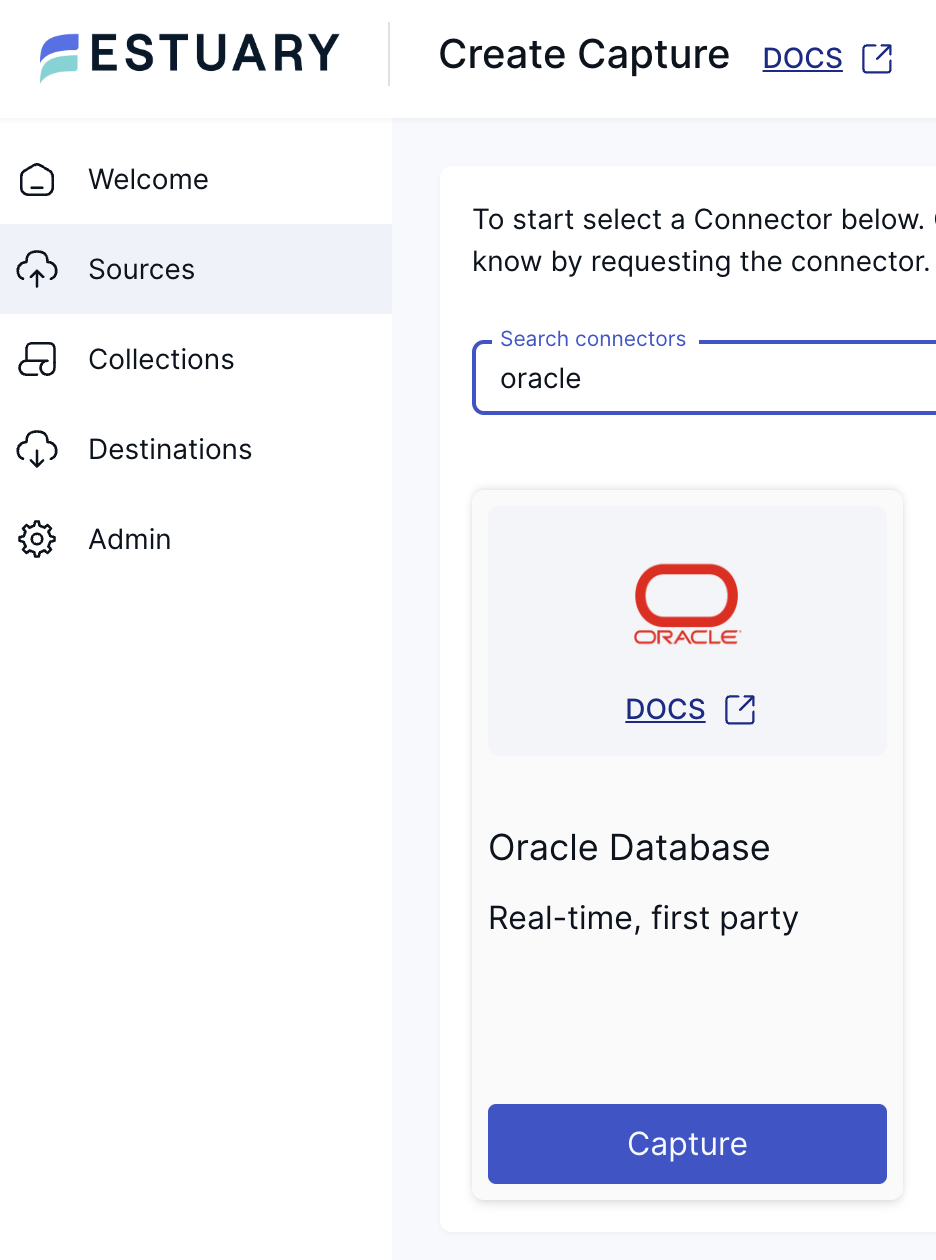
During the endpoint configuration, use the URL of your Oracle instance as the Server Address. For the user/password combination, enter what you configured in the previous step. After pressing next, in the following section, you can configure how the incoming data should be represented in Flow as collections.
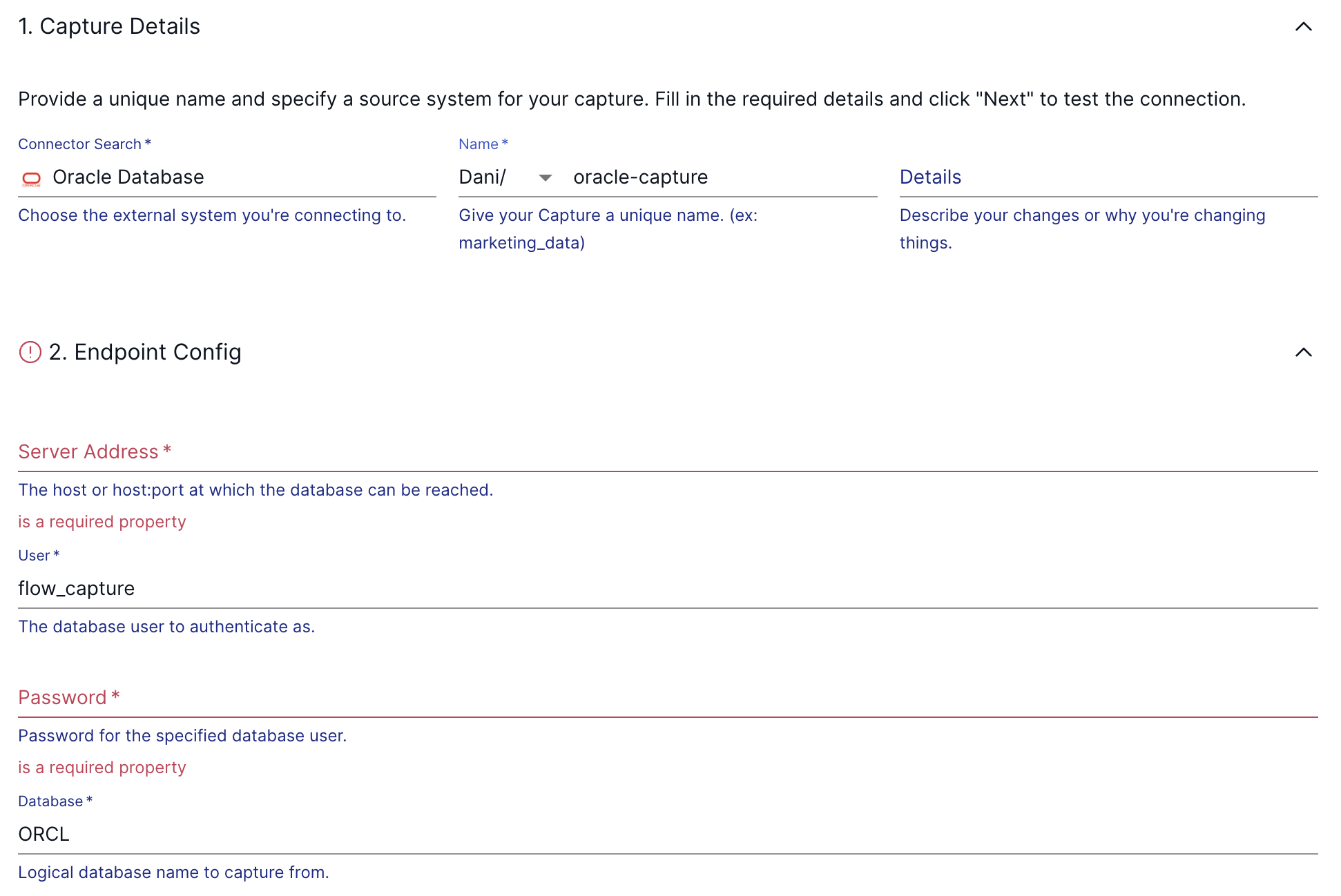
The captures run continuously. As soon as new documents are made available at the endpoint resources, Flow validates their schema and adds them to the appropriate collection.
Estuary Flow writes all change data into collections, which are append-only durable logs similar to a Write-Ahead Log (WAL). Like replication, Estuary Flow transactionally guarantees change data, including the modified chunks.
Collections are a real-time data lake. Documents in collections are stored indefinitely in your cloud storage bucket (or may be managed with your regular bucket lifecycle policies). This means that the full historical content of a collection is available to support future data operations, whether planned or unplanned.
Once you finish creating the capture, let it run for a few seconds, and you should see a stream of INSERT, UPDATE, and DELETE operations in the dashboard!
If your collection is empty or you suspect something might be wrong with your setup, try using Flow’s built-in collection inspection tool. It can be accessed by clicking on the name of the collection you want to inspect.
Step 2: Setup Estuary Flow as a Source in Materialize
Now that your Oracle source is up and running, let’s set up Materialize to ingest change events from Estuary Flow. Head over to the Materialize Console and in the SQL Shell, execute the following steps.
- Create a Source in Materialize. Create a source that connects to Estuary Flow via Kafka API compatibility:
CREATE SECRET estuary_refresh_token AS
'your_generated_estuary_access_token_here';
CREATE CONNECTION estuary_connection TO KAFKA (
BROKER 'dekaf.estuary.dev',
SECURITY PROTOCOL = 'SASL_SSL',
SASL MECHANISMS = 'PLAIN',
SASL USERNAME = '{}',
SASL PASSWORD = SECRET estuary_refresh_token
);
CREATE CONNECTION csr_estuary_connection TO CONFLUENT SCHEMA REGISTRY (
URL 'https://dekaf.estuary.dev',
USERNAME = '{}',
PASSWORD = SECRET estuary_refresh_token
);
CREATE SOURCE sales_source
FROM KAFKA CONNECTION estuary_connection (TOPIC '<name-of-your-flow-collection>')
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY CONNECTION csr_estuary_connection
ENVELOPE UPSERT;- Create an indexed view. Next, define a view that calculates aggregate sales metrics, and create an index on it to keep the results incrementally up-to-date and available in memory for quick serving:
CREATE VIEW aggregated_sales AS
SELECT
customer_id,
SUM(total_amount) AS total_sales,
COUNT(*) AS num_purchases
FROM sales_source
GROUP BY customer_id;
CREATE INDEX idx_aggregated_sales ON aggregated_sales(total_sales);- Query the View.
Subscribe to the
aggregated_salesview to see the results changing in real-time, as new data is propagated from the upstream Oracle database via Flow:
SUBSCRIBE TO (SELECT * FROM aggregated_sales WHERE total_sales > 1000);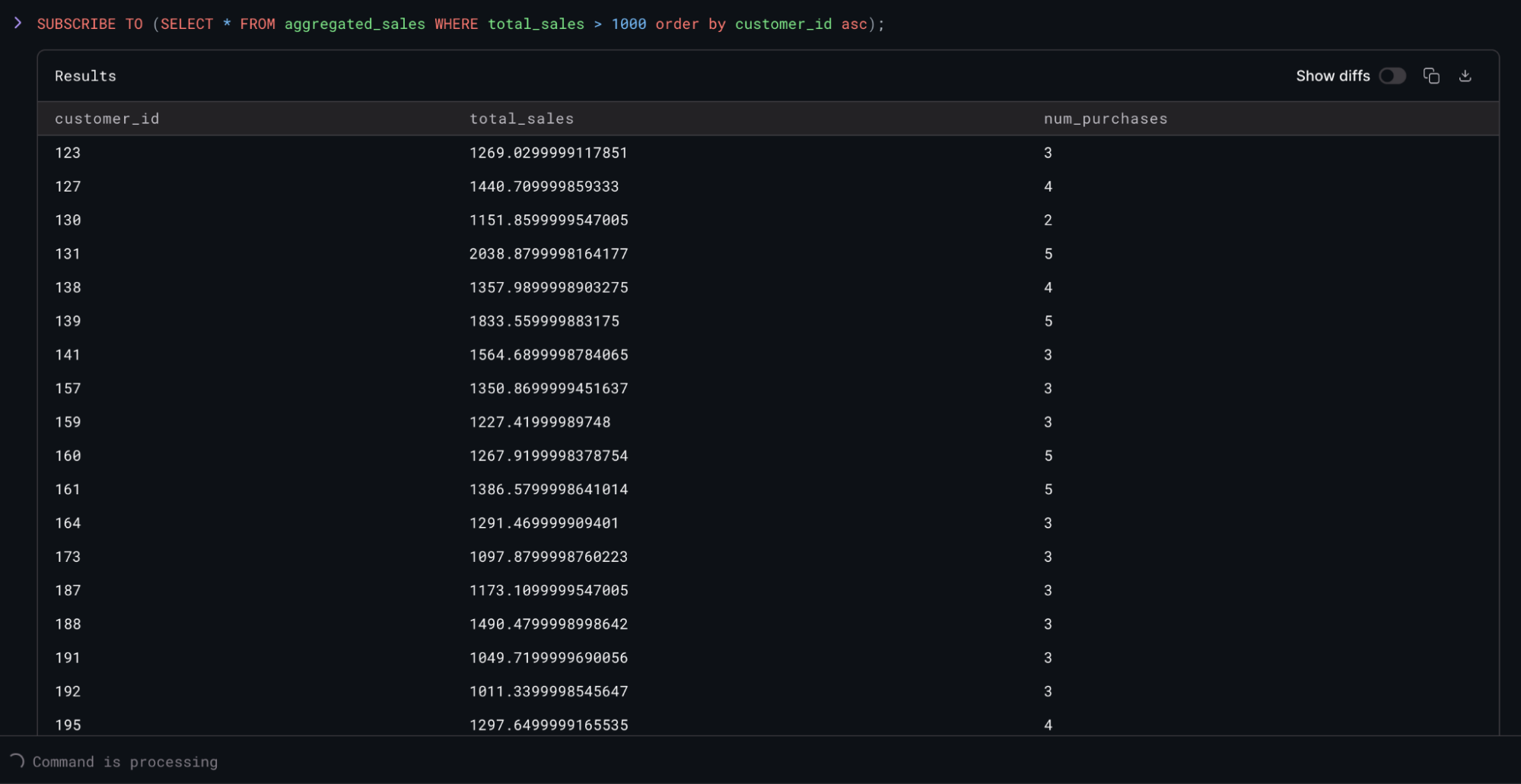
Congratulations, you’ve successfully set up a real-time data pipeline from Oracle to Materialize using Estuary Flow!
Try Estuary Flow & Materialize for Operational Use Cases with Multiple Data Sources
By combining the power of Estuary Flow’s CDC capabilities with Materialize’s ODS capabilities, you create a robust system for ingesting, transforming, and analyzing your data as it changes.
This setup is scalable and can be expanded to include multiple data sources, making it ideal for modern data architectures that require fresh data and SQL support. Try adding more tables to your capture or creating new transformation views in Materialize.
To see Materialize and Estuary Flow power operational use cases with multiple data sources, sign up for free trials of Materialize and Estuary Flow.


