


Online Transaction Processing (OLTP) is a data processing method that powers most of the transaction-based applications we use on a daily basis, including online banking, ATMs, and ticketing systems.
OLTP databases can perform thousands or millions of simple transactions simultaneously, such as withdrawing money from an account. OLTP executes these transactions in near real-time, often in milliseconds.
However, when OLTP databases strain, they can slow down transactions, or even cause downtime. This is unacceptable, since OLTP databases are at the core of a company’s business operations, supporting payment systems and other critical infrastructure.
OLTP databases strain when they perform complex queries. OLTP is designed for simple queries, such as adding two values together. Complex queries require more computational resources. The strain of complex queries can slow or stop transactions that fuel essential business processes.
To solve this problem, teams resort to OLTP offload. OLTP offloads remove complex queries from OLTP databases and execute them on other data platforms. This makes OLTPs faster and more stable, while potentially saving costs.
In the following guide, we’ll give a full overview of OLTP offloads, including different methods teams employ.
Refresher: OLTP Architecture
Online transaction processing (OLTP) is a type of data processing that enables the rapid execution of database transactions. A database transaction is a change, insertion, deletion, or query of data in a database.
OLTP databases must always be available, correct, and low latency to keep a business operational. “Online” means that these database transactions occur very quickly — often in milliseconds. This is why OLTP is ideal for transactions such as purchases, reservations, and deposits.
OLTP systems are concurrent, in that users cannot alter the same record at the same time. They are also atomic, in that if one step during an operation fails, the entire transaction fails. When a transaction fails, all of the changes are rolled back. This helps banking platforms, POS systems, and other transaction-based apps prevent discrepancies. Other key features of OLTP systems include:
Rapid processing
Simple transactions
Multi-user accessibility
Continuous availability
Indexes for fast data access
OLTP systems can scale to handle a high volume of basic transactions. But long-running jobs that churn through a large volume of data, such as analytics and reporting, can tax OLTP systems. This can cause performance issues, including slow rate of transaction approval or user abandonment.
What is OLTP Offload?
This is how OLTP systems can easily strain due to read query-intensive workloads. As teams start to run more complex queries on OLTP databases, the services offered by the system begin to deteriorate.
The OLTP database slows down and destabilizes when performing complicated queries that join across tables, filter across time windows, and compute aggregations. As a result, teams need to scale up their operations. They must buy more software and hire more workers. This is expensive, but often unavoidable, since OLTP systems are mission-critical.
OLTP offloading helps boost overall system performance by moving these complex queries to a separate system. This prevents, for example, expensive queries (i.e. high compute) slowing down the recording of new orders.
In a nutshell, OLTP offloading reduces complex queries on the primary OLTP system. That enables it to do what it does best: process simple read/write transactions at an incredibly high volume.
Method of OLTP Offload
There are a few ways you can offload your expensive query workloads to ensure better performance of your OLTP transactions. Let’s look at the benefits and downsides of each one by one.
Method 1: The Queries Happen on the Primary Database
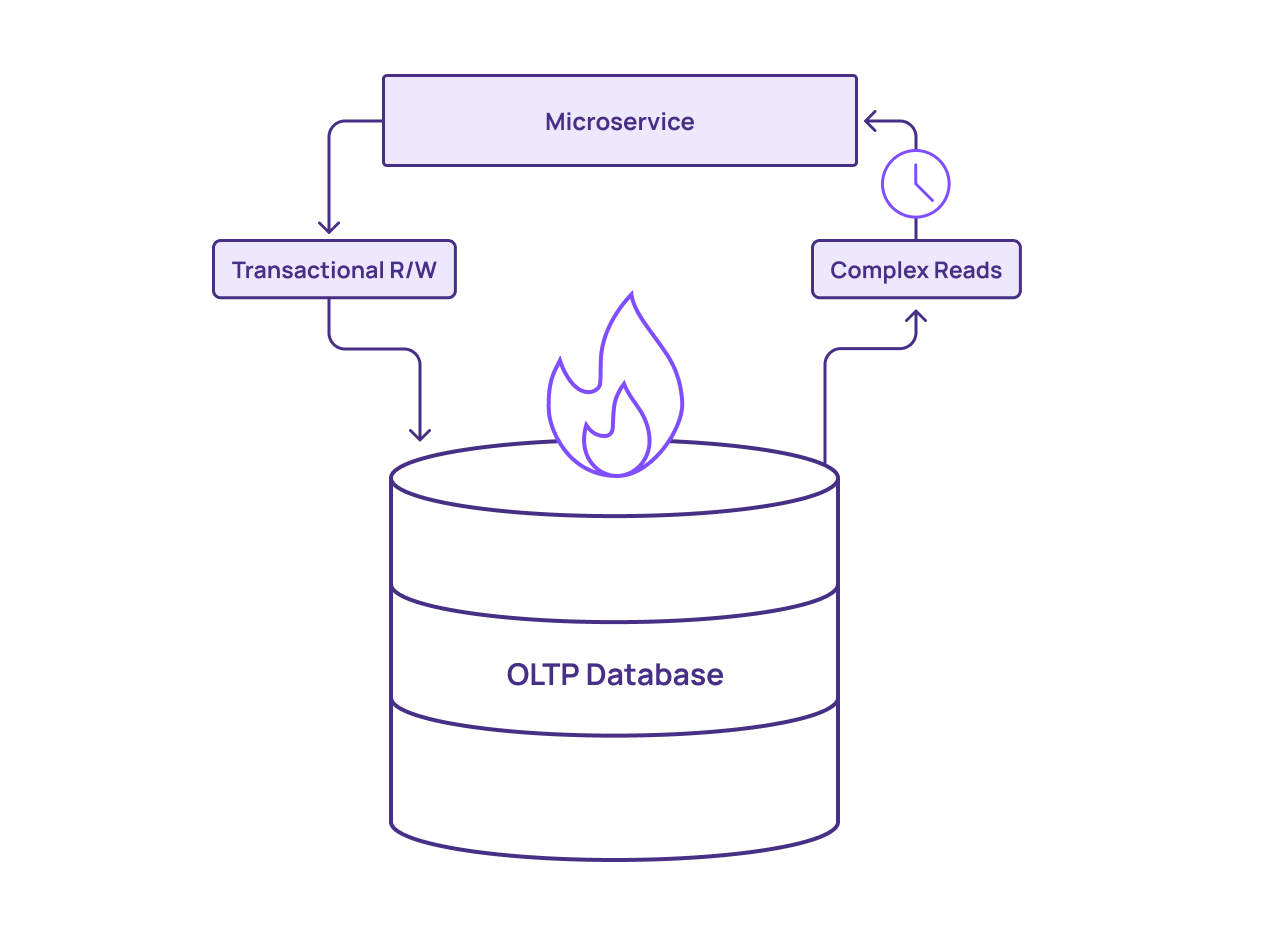
In this first method, you perform queries in-place, on the primary production database. This approach can work, but has two major downsides:
Slower - Performing expensive queries on the primary database, which is already busy processing OLTP transactions, can result in slower transactions. This can harm data freshness.
Unstable - The additional load of running non-OLTP workloads on the OLTP system could overwhelm it, potentially leading to inconsistent results and costly downtime.
However, you change the configuration of the database — or even of the data itself — to make these complex queries more efficient. Here are three ways to accomplish this:
Create additional indexes. Creating additional indexes on key search fields (e.g., dates, transaction amounts, etc.) can result in faster read performance. That’ll lower the overall load on your database. The downside is that additional indexes slow down writes. That could result in less of a performance boost than you’d expect.
Denormalization. In this pattern, you offload data from multiple tables into another table or outside of normal form to make reads faster. Using a flattened structure for data eliminates joins and accelerates data queries. You can write out data in batches as a background job or set up a trigger to duplicate changes on write. While this approach works, it leads to data staleness and complexity. This requires data engineers to develop and maintain an ETL pipeline to a separate system and schedule refreshes. This is fine for certain historical analytics, but is not viable for use cases that require fresh results.
Materialized views. A materialized view will do the up-front work of denormalizing data. However, refreshing the view will cause additional load on the database and may reduce your performance boost.
When you perform queries in-place, data freshness suffers, UIs won’t match customer actions, and reports will be out of date. Updating the materialized view also creates load on the database. As you recompute views more frequently to get fresher results, you’re basically just re-running queries constantly.
Method 2: Scale Up Database
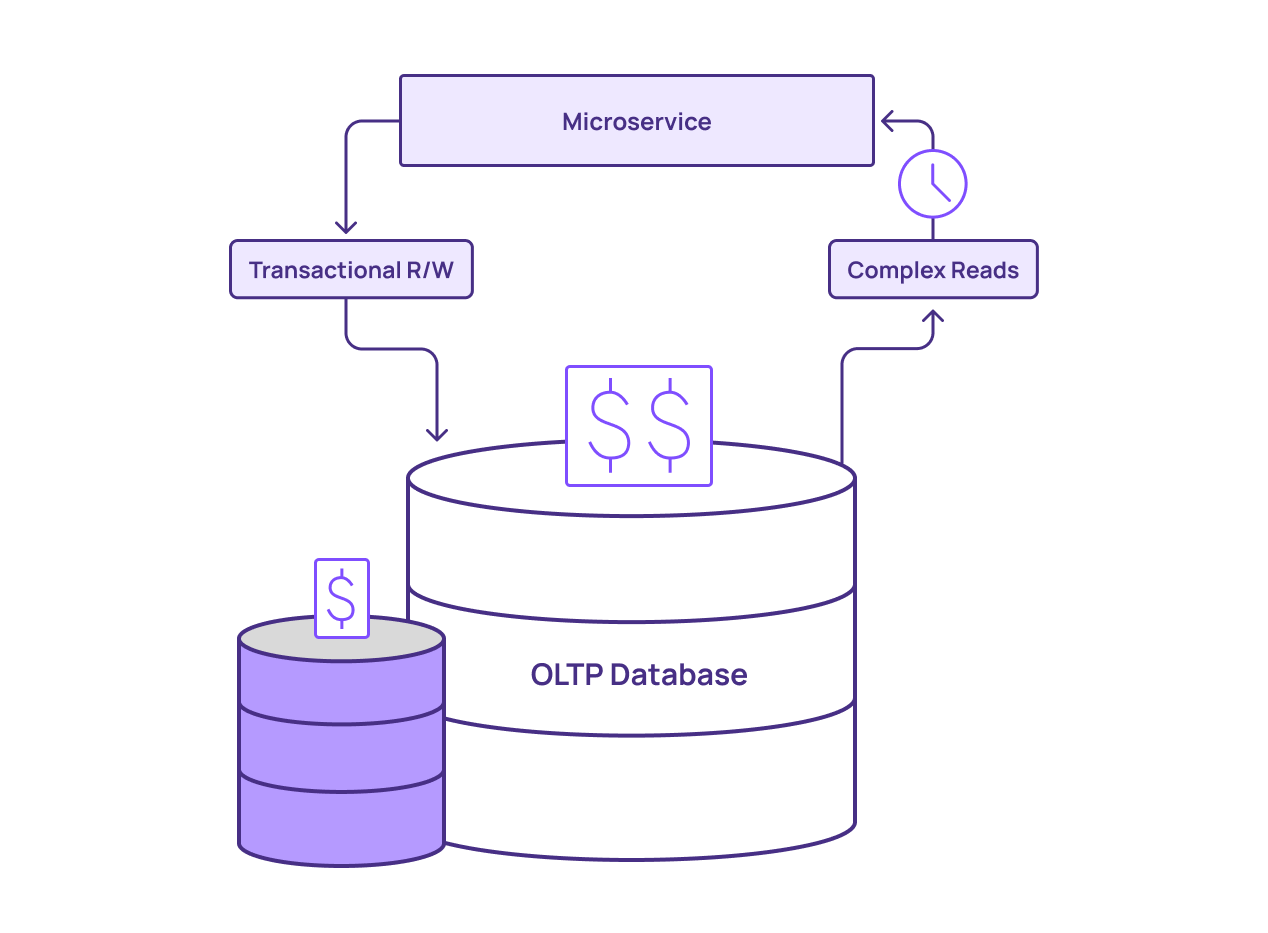
As another option, you can scale up the primary database. You can scale out horizontally, as in adding more computing instances to process incoming transactions. You can also scale out vertically by increasing the size of existing instances — using instances with more processing cores and memory.
While this also may work in the short term, it’s a limited approach. OLTP databases, at their core, aren’t designed to deal with complex queries. However, it can get you over the hump, avoiding errors and downtime while you work on a more robust offloading approach.
Method 3: The queries happen on a replica of the primary OLTP database
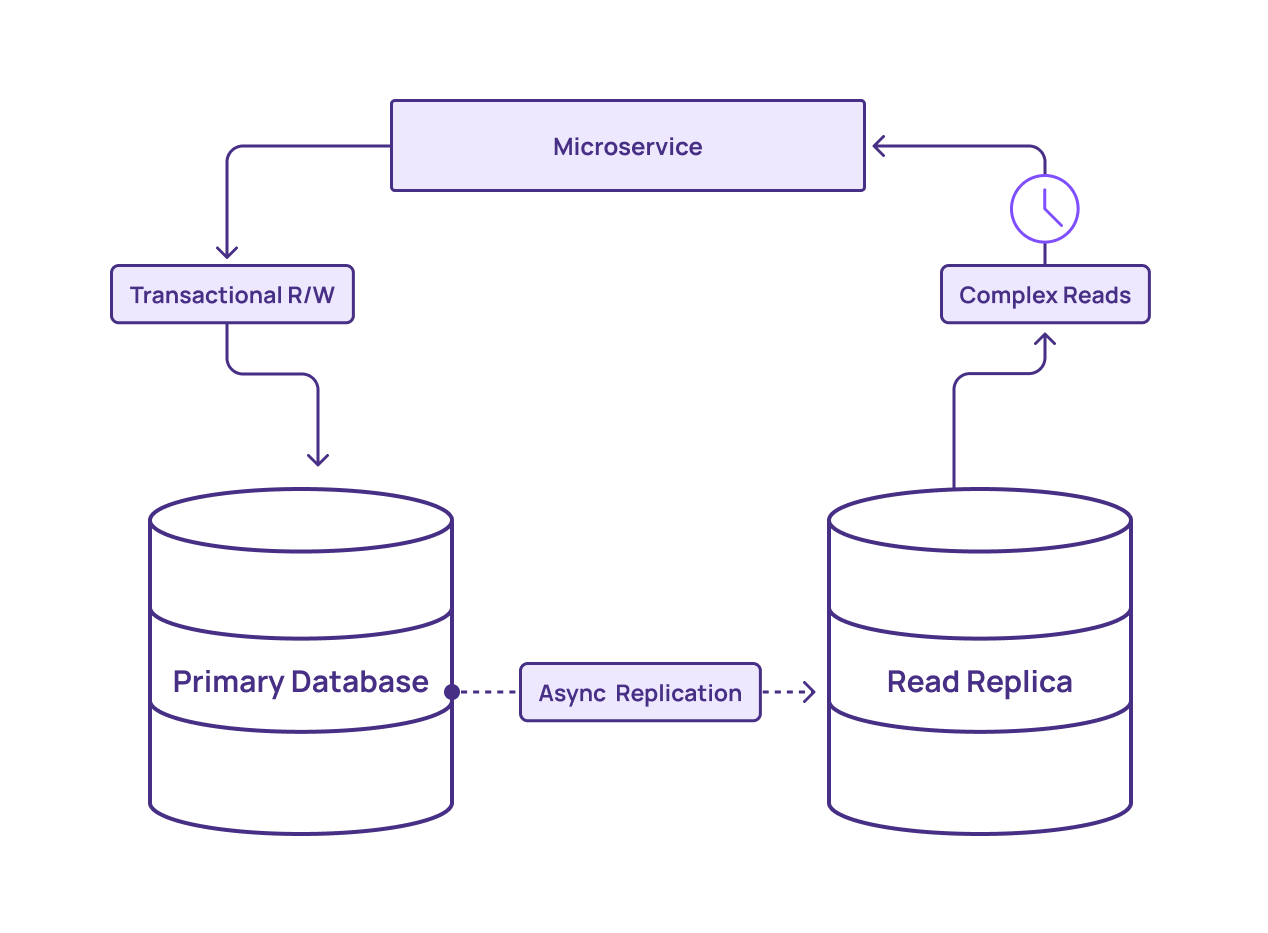
In the third approach, you offload non-OLTP work from the primary database completely and move it to a read replica. This removes read-heavy loads from the OLTP system, providing more computing capacity and memory to process writes.
This represents an improvement over the first method, as it offloads significant stress from the primary database. However, it still comes with several drawbacks:
The read replica uses the same architecture as the primary database. If a query is so complex that it doesn’t run well on the primary, it may not run much faster on the replica, even with the extra processing power available. You can workaround this by scaling out your read replica to additional instances. However, this introduces additional complexity and costs
Using read replicas raises the total cost of your solution. Each replica consumes storage and compute cycles that grow more expensive as you grow out your replica cluster. If you can’t obtain high utilization out of each instance, using replicas may prove too expensive to be worthwhile.
Additionally, read replicas require constant refreshing from the primary database. The more read replicas you add, the more stress you add to the primary database. In other words, adding more replicas can actually contribute to the problem you’re trying to solve (workloads on the database).
Our customer Centerfield a digital marketing and analytics company, encountered issues with read replicas. The company built the majority of its analytics processing around a central SQL database. They continued to add read replicas, but reached a point where this method could not meet the growing demands of the business.
Method 4: Analytical Data Warehouse
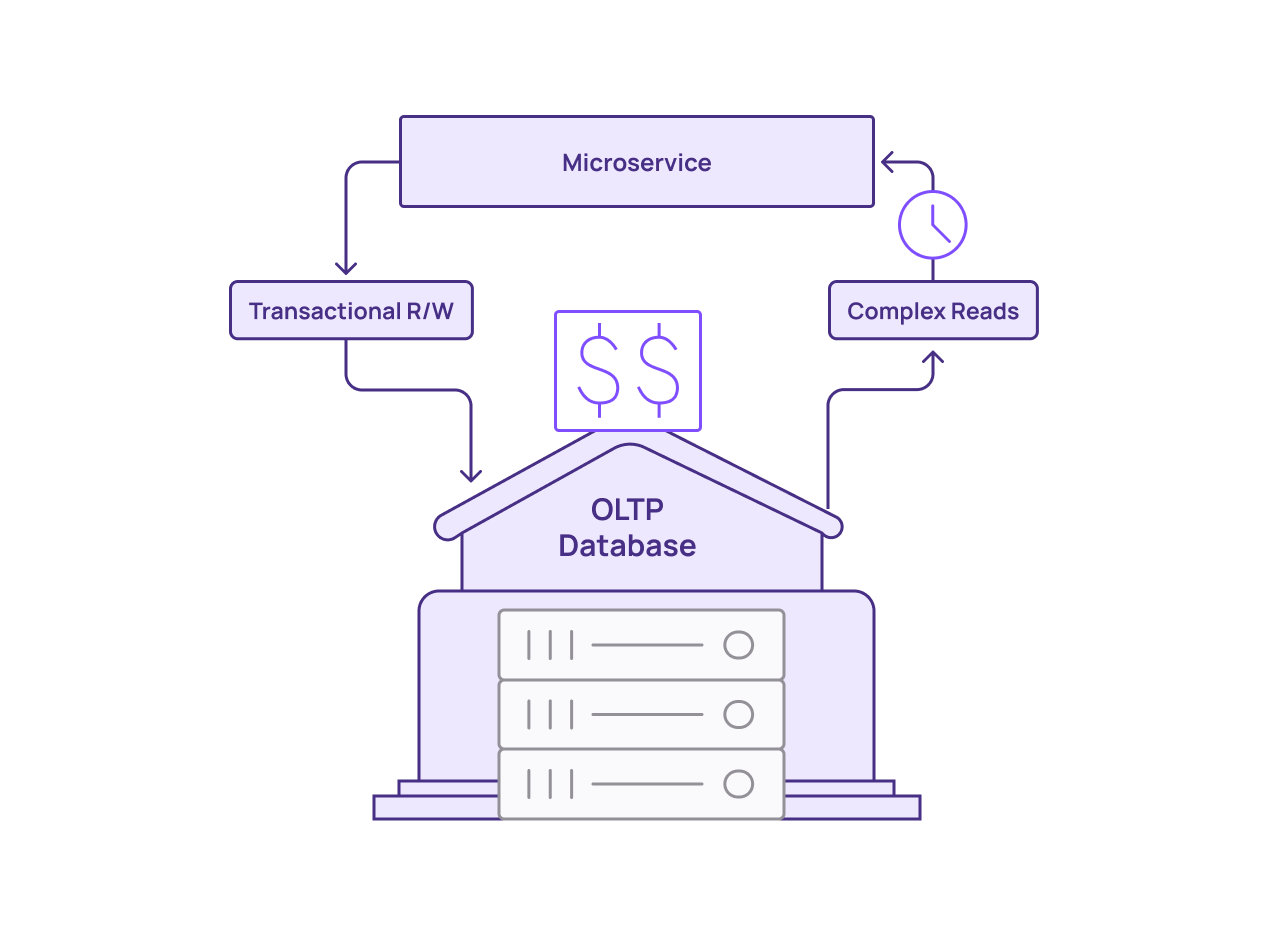
Complex queries are not ideal for OLTP systems. But analytical data warehouses are built for these kinds of queries. Teams can perfect SQL logic in their analytical data warehouses using historical data. It’s also not uncommon for teams to use analytical data warehouses to perform OLTP offloads.
Although analytical data warehouses offer more stability than OLTP systems, they also come with their own limitations:
Analytical data warehouses eventually reach a hard limit on data freshness. They run on batch processing, and to approach the freshness needed for OLTP, they must constantly run data updates. Although this generates fresher data, the data updates can only occur so fast. This leads to inadequate data freshness.
Operating in a pay-per-query pricing scheme, analytical data warehouses can generate high costs when performing OLTP offloads. Constantly re-executing queries and updating data for fresh results can create a growing cost center.
Analytical data warehouses can handle the complex queries that overwhelm transactional systems. But issues with data freshness and costs make them a less appealing choice for OLTP offloads.
Method 5: Operational Data Warehouse
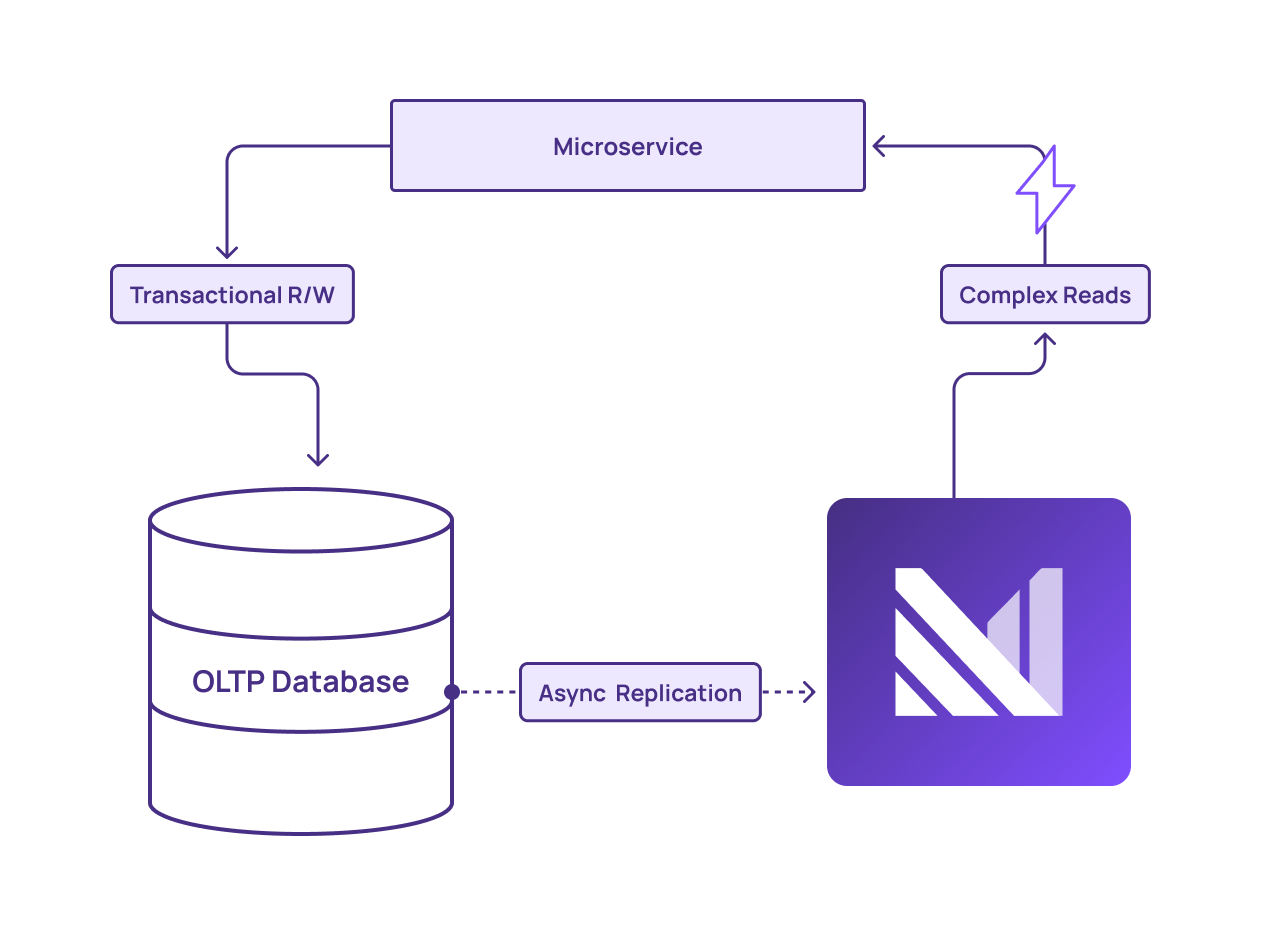
By offloading the queries from an OLTP system to Materialize, organizations can improve the resilience and performance of their core services while ensuring fast and fresh query results. Materialize enables a more efficient and reliable data handling process, keeping core operations smooth and responsive.
Materialize combines the power of streaming data with SQL support. With Materialize, teams can access the familiar interface of a data warehouse, but powered by fresh data, as opposed to batch data warehouses that update data every few hours.
Materialize provides multiple benefits over the methods listed above:
Low latency - Results are returned by Materialize in milliseconds, the same range as OLTP databases. This ensures data freshness and allows critical business processes to run uninterrupted.
Data warehouse architecture - Materialize executes arbitrarily complex queries over streaming data, meaning the results are fresh enough to be used in OLTP workflows.
Strong consistency - Materialize’s consistency guarantees mean that the results of complex queries are always correct, matching the accuracy needed for OLTP systems.
Incremental View Maintenance (IVM) - Materialize incrementally updates materialized views as new data streams into the system. This limits the amount of work the data warehouse does, and allows materialized views to always stay up-to-date.
Command Query Responsibility Segregation (CQRS) - A Command Query Responsibility Segregation (CQRS) pattern that sends the writes to the core database, and the reads to Materialize. This allows teams to save money by scaling down their main database.
For workloads that benefit from fresh data, offloading to Materialize can free up cycles from your OLTP system without the negative performance/cost implications of using primaries or read replicas. Materialize offers full SQL support and postgreSQL compatibility.
This includes both the expressiveness of the SQL, including window functions and recursive SQL, as well as wire protocol compatibility, allowing users to leverage their favorite database tools off the shelf.
Materialize: Easily Offload Expensive OLTP Queries
In summary, while there are numerous ways to perform OLTP offloading, most have a significant downside or contains gaps:
Using your OLTP primary puts additional load on your OLTP database, which could result in performance degradation or downtime for this mission-critical system
Scaling up your OLTP primary doesn’t address the root problem, which is that OLTP systems weren’t mean to handle complex queries
OLTP read replicas don’t get around the design limitations of OLTP systems, which results in rising costs as you scale up
Analytical data warehouses are good for analytical workloads but don’t cover use cases where data freshness is measured in milliseconds
Materialize is an operational data store that enables full offloading of non-OLTP workloads from your OLTP systems. This enables your OLTP systems to focus on serving simple read/write queries at high volume, while Materialize handles complicated, read-intensive workloads.
For a full overview of OLTP systems, and additional information about offloading options, download our free white paper on the topic, OLTP Offload: Optimize Your Transaction-Based Databases.